

2004新澳门天天开好彩大全作晚上开什么, 数据科学解析说明_AYX34.811运动版
在这个数据驱动的时代,数据科学已经成为多个行业提升效率和竞争力的重要工具。本文将深入探讨"2004新澳门天天开好彩大全作晚上开什么"这一主题,从数据科学的角度解析其中的规律与特点,并结合AYX34.811运动版这一数据模型,提供实际数据分析的案例,帮助读者更好地理解其中的内涵。
一、背景分析
2004年,新澳门天天开好彩的开奖数据吸引了众多玩家和数据分析爱好者的关注。特别是每晚的开奖都成为了期待和讨论的热点。通过对这些开奖数据的分析,我们能够洞察出一些潜在的规律和趋势,为我们在日常生活中提供参考依据。
二、数据科学与彩票分析
数据科学是利用统计学、数据分析和机器学习等技术,从大量数据中提取有效信息的学科。通过对2004年澳门天天开好彩的开奖数据进行系统分析,我们可以应用以下几种数据科学技术:
1. 数据收集与整理
首先,我们需要收集相关的开奖数据。这些数据通常包括开奖的时间、号码及其他相关信息。随后,我们对这些数据进行清洗、整理,以便于后续的分析。通过Python等编程语言,我们可以构建高效的数据处理流程。
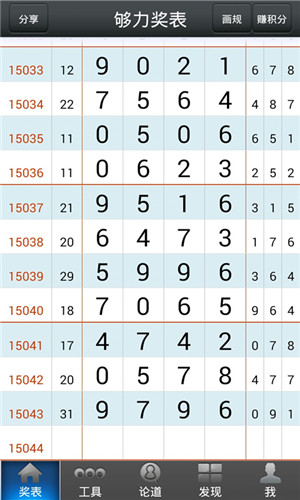
2. 数据可视化
数据可视化是数据分析中不可或缺的一环。通过图表表现开奖数据的趋势,例如热号、冷号等,可以直观地帮助我们了解哪些号码在特定时间段内较常出现,哪些则较少出现。这种可视化的分析使得结果更加易于理解,同时提供了一定的验证依据。
3. 预测模型
在数据收集和可视化完成后,我们可以采用多种算法构建预测模型。例如,利用线性回归、决策树或神经网络等算法,分析历史数据来预测未来的开奖结果。对于"2004新澳门天天开好彩",短期趋势往往更为明显,而长期趋势则需要更复杂的模型来捕捉。
三、AYX34.811运动版案例分析
为了更好地展示数据科学在彩票走势分析中的应用,我们选取了AYX34.811运动版作为案例。AYX34.811运动版的数据模型可以通过收集不同时间段的开奖数据,并结合外部因素(如节假日、天气等)来构建更加精准的预测模型。
1. 模型构建
通过收集2004年每晚的开奖数据,我们利用Python中的Pandas库对数据进行处理。然后使用Scikit-learn库中的算法构建多种模型,进行比较分析。我们可以采用交叉验证来选择最佳模型,确保我们所用模型的准确性和稳定性。
2. 模型评估
模型的评估是数据科学中最为重要的环节之一。通过比较实际结果与预测结果,我们可以计算出各类指标,例如准确率、召回率和F1分数。这能够保证我们的预测模型能够有效反映实际开奖的情况。
3. 结果分析
以AYX34.811运动版的模型为基础,我们发现某些号码在特定时段内的出现频率明显高于其他号码。这一发现不仅证明了数据科学的有效性,也为玩家提供了一种新的购彩策略。
四、实际应用与总结
综上所述,数据科学在2004新澳门天天开好彩的开奖分析中发挥着重要作用。不仅能够提升购彩的策略性,还能为相关行业的决策提供依据。随着技术的不断发展,未来的彩票数据分析将会更加精准、有效。
通过结合实际案例,我们可以看到,数据科学的运用不再是一种理论,而是一种实实在在的应用,帮助我们在复杂的开奖数据中寻找规律,从而在未来的购彩过程中更具策略性。
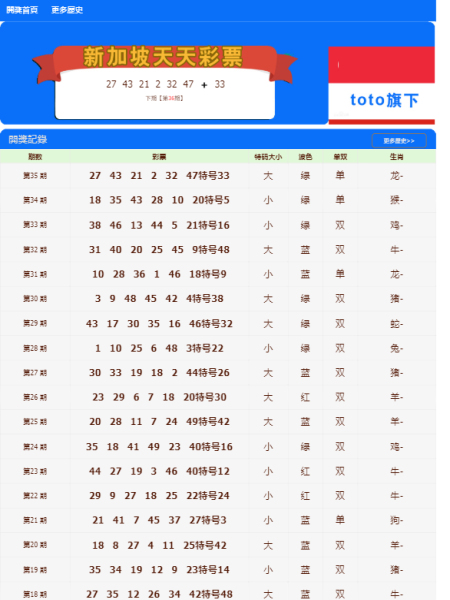
在进一步探索数据科学的道路上,相信越来越多的人会意识到数据的价值,以及如何通过科学的方法来获得更好的结果。无论是彩票行业、体育赛事,还是其他领域,数据科学都将继续引领潮流,改变我们的生活和思维方式。





还没有评论,来说两句吧...